

Software development productivity is a top concern for any modern technology organization, but it can be difficult to pin down. Everyone can see when a team is struggling or a project is falling behind schedule, but determining why is a challenge.
In this article, we introduce a productivity stack for software development. This framework separates the activities that impact productivity from each other to clarify who should be responsible for each layer and make diagnosing delays much easier.
Here we describe the activities in each layer of the productivity stack along with the outputs it provides to the next layer and common problems that create overhead. We also talk about how to measure activity at each layer to help improve overall productivity.
The Stack Abstraction
You may be familiar with the idea of a protocol stack from networking. In a protocol stack, each layer is isolated from the others and provides a useful abstraction like addressing or reliable delivery.
In a healthy stack, each layer can rely on the ones below it to do their jobs without having to worry about the details. Lower layers have the freedom to optimize as long as they provide consistent semantics to the higher layers.
A healthy software engineering organization should work the same way. Different activities should form a productivity stack where each layer offers a consistent interface to the one above it, providing the same reliability and isolation as a network protocol stack.
The Software Development Productivity Stack
Here is a high-level diagram of the software development productivity stack, which shows the different layers. In the sections that follow, we will go into more detail about what is in each layer and how the layers interact.
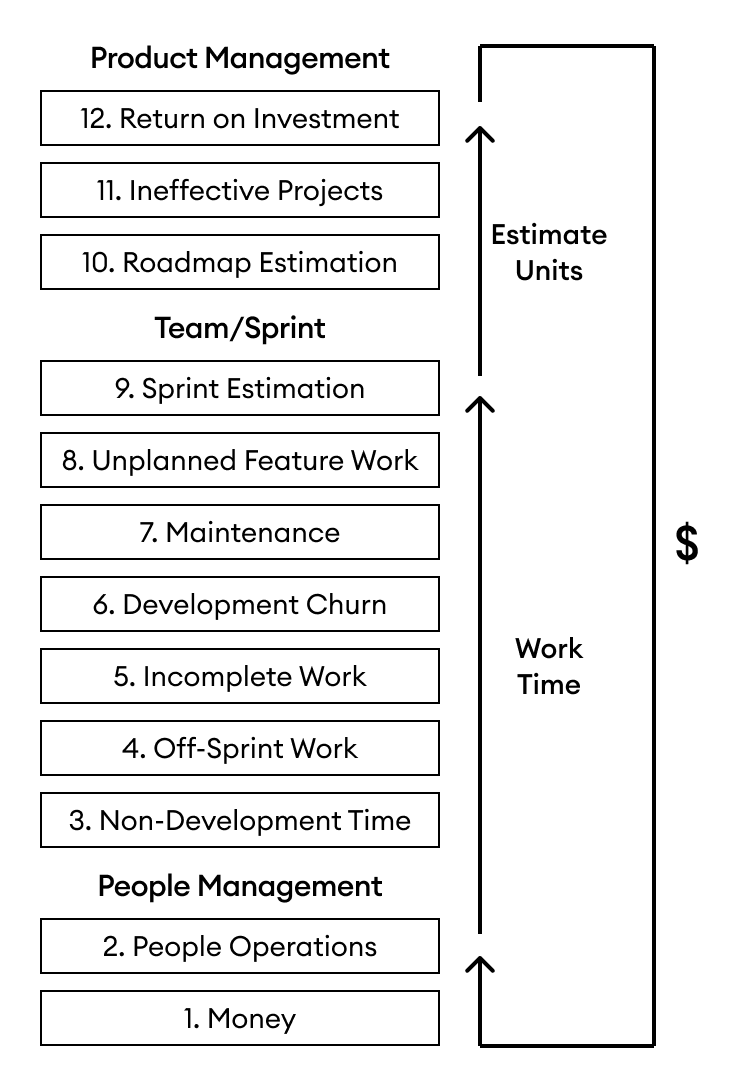
Why Use a Stack?
One way to analyze software development activity would be to just look at how much effort is spent on each type of activity, like fixing bugs, attending meetings, etc.
The problem with measuring activities in the absence of a stack is that it prevents you from seeing what portion of available time goes toward each one.
For example, if you just use a traditional sprint report, you might see that 80% of story points completed by a team went toward new feature development, which seems healthy.
However, without a stack, you won’t know the denominator for that 80%. It could be that the team spent 25% of its time on non-development work (like answering support escalations and random meetings) and 30% on tasks that were not ticketed in the sprint. The non-feature tickets might have also taken twice as long per estimated story point due to technical debt.
At the end of the day, this hypothetical team only spent 35% of its time on new feature work, even though conventional metrics show 80%! It is crucial for engineering teams to look at each productivity stack layer in isolation to get an accurate and complete picture of team efficiency.
The People Management Layers
The first layers of the productivity stack involve business and people management activities that are necessary precursors to software development. Responsibility for optimizing these layers falls on the people management chain at the organization.
Layer 1: Money (or Other Resources)
The foundation of the productivity stack is money or other resources necessary to employ engineers. Money could come from debt, equity, revenue, or donations.
Even open-source projects need to recruit engineers based on a sense of purpose or offering other benefits like career experience – not unlike soliciting donations for a non-profit.
The money layer provides cash or other resources to the next layer.
We won’t go into detail here about what can go wrong at this layer, but it’s important not to forget that the entire productivity stack rests on the resources that go into it.
Layer 2: People Operations
Older companies use the term “human resources,” but modern technology firms (starting with Google) have adopted a people operations approach to attracting, retaining, and developing talent.
People operations goes beyond human resources by recognizing the value such an organization can provide helping people succeed – not just protecting the company from legal issues like old-school HR departments.
The people operations layer takes in resources from layer 1, and delivers motivated and talented people.
For people operations to succeed at recruiting, it needs to create a strong employer brand to generate demand, and then properly screen candidates to select those that are the best fit for the role.
Once employees are hired, people operations is responsible for quickly and effectively onboarding people so that they are able to ramp up to full productivity.
For current employees, people operations must offer career development, adequate compensation, benefits, and a healthy work environment so that people are excited to show up and give their best effort every day.
Finally, the way that people operations handles employees who aren’t performing well or integrating with the culture is critical not just for utilizing available headcount effectively, but also maintaining the morale of higher-performing employees.
While we refer to this layer as people operations, it extends beyond the people operations department and includes a lot of the work that engineering managers perform with recruiting, training, career development, and maintaining morale.
The Team/Sprint Layers
The next set of layers involve activities that transform people’s time into completed units of planned software development work. These layers are managed by the individual software development team.
This is typically the group of people who participate in “sprints” if the team uses the scrum methodology. However, if the team doesn’t use sprints, then this is just the group of people who complete work and evaluate progress at some cadence.
Layer 3: Non-Development Time
Before engineers can do engineering, they need to satisfy the other requirements of being a member of the organization.
Non-development time includes a lot of different things, such as time off for vacation and breaks, helping with people operations (e.g., interviewing, participating in performance reviews, one-on-ones with managers, etc.), social activities, training, and other meetings like all-hands. It also includes important team meetings for things like sprint planning and retrospectives.
Having zero non-development time would clearly be unsustainable and undesirable, but it’s important to make sure that this time is adding value and not overly burdensome for developers. It is further important to make sure that the remaining development time is concentrated in longer blocks rather than abbreviated by frequent non-development obligations.
The non-development layer takes in 100% of people’s time from layer 2, and delivers a consistent amount of time for core work activities to the next layer – preferably in longer blocks to maximize development productivity.
To this end, teams should track the amount of time spent on non-development activities each week or sprint by looking at things like meetings and activity from non-development tools such as document management systems. The goals here are twofold: to evaluate and reduce unproductive non-development time, and to provide a predictable and consistent amount of development time to the next layer.
Layer 4: Off-Sprint Work
In any real team that is responsible for active production software, people will often get pulled into various tasks that may not be added to the sprint (or list of planned tasks if not using sprints), or may not even have tickets in the project management system.
This could come from answering questions from outside of the team, responding to incidents, working on deployments, or simply exploring ideas of personal interest.
While it’s important not to neglect these other activities, teams should strive to make sure anything substantial is represented with a ticket in the sprint/team ticket list to provide tracking and visibility.
The off-sprint work layer starts with development time from layer 3, and leaves development time on ticketed work in the sprint for the next layer.
Layer 5: Incomplete Work
Regardless of the type of work, tickets that start but do not finish take away from the team’s capacity and can reduce output metrics even if the work is completed at a later time.
One form of incomplete work is development that never gets merged into production. Code can be abandoned for a number of reasons and it’s better to abandon bad code than ship it to make the numbers look good, but teams should keep a close eye on significant amounts of unlaunched code and assess why it was abandoned.
A less detrimental but still important type of incomplete work is tickets that don’t make it over the finish line by the end of the sprint/development cycle. This can result in delays getting code to customers and increase the overhead of work in progress.
The incomplete work layer starts with all ticketed development time from layer 4, and leaves time that goes toward finished tickets.
Layer 6: Development Churn
This layer represents development work that took longer than it should have (whether or not this was accounted for in the estimate).
The goal of this layer is to account for how much time the development team could save by resolving issues that slow down development.
It can be difficult to assess how long tasks should take because many of the problems that arise are handled during the course of working on a ticket. (However, some are not ticket-specific like struggling with a development environment.) Things like technical debt or skill set mismatches can have a significant impact, but are hard to measure, particularly if they don’t cause a task to go past its estimate.
One strategy for measuring what we call development churn (tasks taking longer than they should) is to ask people what percentage of time they feel like they wasted. Additionally, you can look at metrics like time spent on merging and time spent on code that was deleted before merge for more direct evidence of development churn.
The development churn layer starts with all sprint capacity from layer 5, subtracts inefficient development effort, and leaves productive sprint capacity.
Layer 7: Maintenance (a.k.a. Keep the Lights On)
The next layer includes all of the work that teams have to do to keep their software running successfully for their customers.
This layer includes bug fixes, incidents, customer support escalations, and handling other regular maintenance requests like updating configuration when it is not self-service.
Part of successful maintenance is ensuring that the software meets quality standards such as uptime, time to handle support requests, etc., so analysis of this layer should include quality metrics in addition to time spent on maintenance.
While there may be some discretion about when to fix non-urgent bugs, whether or not maintenance work was included at the start of the sprint does not have a material impact on time available for higher layers in the long run, so we include both planned and unplanned maintenance work in the same layer.
The maintenance layer starts with productive sprint capacity from layer 6, and leaves capacity for improvements.
Layer 8: Unplanned Feature Work
Scrum advocates planning the scope of work at the beginning of each sprint/development cycle.
It isn’t necessarily bad to add tickets to a sprint after it starts; it is better to change plans than stick to a bad plan. However, this means that the team did not predict the work, so it has implications for how much time it might take to complete planned work in the future.
There are many potential causes for unplanned feature work. It can occur due to lack of diligence from the product manager in identifying requirements up front, similar lack of diligence from outside stakeholders, or unpredictable forces that change business requirements.
Oftentimes, the source of unplanned work is the engineering team itself. This can happen if engineers fail to adequately plan the architecture and mitigate risks up front, which leads to unexpected increase in scope to handle technical issues.
Whichever way unplanned feature work originates, teams should strive to improve planning so that the work can be predicted at the start of the sprint where possible.
The unplanned feature work layer starts with capacity for improvements from layer 7, and provides capacity for planned improvements.
Layer 9: Sprint Estimation
Unlike previous layers, this one does not subtract overhead, but instead translates the available time from the previous layer into units of estimation.
The sprint estimation layer involves comparing story points, ticket counts, or other units of estimation from completed work to the time that was spent on that work.
The purpose of this layer is to assess estimate accuracy. By comparing the available time for planned improvements to completed story points/estimation units, you can determine whether variability in completed tickets was caused by bad estimation or by issues in one of the earlier layers.
Note: It is also common practice to look at estimate accuracy for maintenance and unplanned feature work. This can help with reducing incomplete work and meeting short-term commitments (i.e., knowing what will be done in the current sprint). However, it isn’t strictly necessary as long as you are measuring time spent on maintenance and unplanned feature work because those tasks are not part of the roadmap.
The sprint estimation layer starts with work time for planned improvements from layer 8, and emits story points/estimation units for completed planned work.
Sprint Layer Summary
Through the sprint layers, teams transform people’s time into completed planned improvements, denominated in story points/estimation units.
By looking at variability in each layer individually, you can quickly attribute inconsistencies in the final output to their source.
Teams should continuously improve each layer over time to deliver an increasingly consistent and predictable capacity for planned work.
The Product Management Layers
The final layers in the development productivity stack utilize team capacity to complete higher-level objectives on the software development roadmap. The product team is primarily responsible for these layers, but should work closely with engineers.
Layer 10: Roadmap Estimation
Before embarking on any larger initiative that spans multiple sprints, product managers should at least have an approximate idea of its size. This may be a singular rough estimate figure, or a series of high-level tickets that will be broken down later.
Larger initiatives typically do not have the same fidelity of estimates that individual tickets do at the start of sprints. Coming up with such estimates would go against the spirit of agile, and they would be less accurate anyway because it is harder to predict further into the future.
The scope creep layer looks at the difference between the rough back-of-the-envelope estimates used to prioritize initiatives on the roadmap, and the number of planned story points/estimation units that ultimately go into sprints for the initiative.
If an initiative’s goals change significantly, then so should its rough estimate so that this layer only reflects the translation from roadmap planning to sprint planning.
Rough roadmap estimates should ideally use the same units of estimation as sprints (e.g., story points) to make scope creep calculations possible. However, it’s important for everyone to understand that those estimates are not as accurate as story point estimates at the beginning of sprints when more information is available. If roadmap estimates are denominated in different units like person-weeks, they should be translated to an equivalent amount of story points based on velocity.
The roadmap estimation layer takes in sprint capacity estimates from layer 9 and produces rough roadmap-level estimates.
This layer makes it possible to realistically assess how much roadmap-level work might be achievable over a longer time period.
Layer 11: Ineffective Projects
This layer of the development productivity stack looks at projects that do not achieve their intended goal of providing value to customers – a.k.a., the failed experiments.
Assessing customer value can be challenging and is highly business-specific. Some companies are able to run A/B tests or other statistical analyses to confidently measure ineffective projects.
Even without sophisticated methods, however, you can still identify projects that were canceled, rolled back, or significantly underperformed customer adoption goals to get a sense of wasted effort.
The ineffective projects layer takes roadmap capacity from layer 10, subtracts roadmap capacity used on projects that added little to no value, and leaves productive roadmap capacity.
Layer 12: Return on Investment
The final layer in the development productivity map comes full circle and connects the productive roadmap capacity back to money.
For contract businesses that produce software for clients rather than harvesting profit from the software they create themselves, it is easy to look at how much money was brought in by each successful roadmap initiative.
For other businesses, accurate return on investment (ROI calculation) is much more complicated.
Even attributing profit generated by an entire software product back to all of its development work is not straightforward. Profit arrives over time, often with much of a product’s value occurring in the future.
One approach used by some businesses is to tie software updates to improvements in core metrics like customer acquisition cost (CAC), churn, average order size, or lifetime value (LTV). These then feed into models that estimate the net impact on business value.
However it's done, the engineering team in any organization will ultimately need to justify its existence. The better it is able to calculate ROI on a per-project basis, the easier it will be to make the broader organization successful.
For organizations like governments and non-profits, value takes the form of other objectives that result in happy sponsors and continued funding if needed.
The return on investment layer takes the productive roadmap capacity from layer 11, and translates it into net value for the organization.
The Bottom Line
Software development productivity is notoriously opaque. Failures are easy to see, but causes of those failures often remain a mystery.
Software development doesn’t have to be a black box if you apply the productivity stack model outlined in this article. By dividing up the engineering process from start to finish into well-defined layers, it quickly becomes apparent where the bottlenecks lie.
With some management diligence, anyone can start analyzing software development using the productivity stack model, and there are tools like minware that help with the process.
If you’ve made it this far, you are well on your way to building a happier and more productive engineering organization.